오늘은 이전에 근무했던 회사에서 진행했던 인프라 전환 프로젝트 경험을 공유하고자 합니다. 운영 중인 서비스의 아키텍처를 Cloud Run (+ Google Tasks)에서 GKE (Google Kubernetes Engine) 기반으로 성공적으로 전환하며 겪었던 문제점과 개선점을 자세히 다뤄보겠습니다.
운영 중인 인프라를 변경하는 것은 서비스 중단과 장애 리스크가 큰 작업입니다. 따라서 저희 팀은 철저한 사전 테스트와 점진적인 마이그레이션 전략을 통해 신중하게 프로젝트를 진행했습니다.
인프라 전환을 결심한 이유
기존 시스템은 여러 가지 심각한 문제들을 안고 있었습니다.
- 치명적인 비동기 시스템 설계: 대량의 트래픽이 몰릴 때마다 오류가 발생하며 서비스 안정성을 크게 위협했습니다.
- 비효율적인 반자동 배포: 배포 과정에 클라우드 콘솔에서의 수작업이 포함되어 있어 비효율적이었습니다.
- 과도한 인프라 비용: 불필요한 인스턴스 확장으로 인해 인프라 비용이 눈덩이처럼 불어났습니다.
특히, 트래픽이 많을 때마다 발생하는 오류는 회사의 매출과 직결되는 심각한 문제였기에, 빠른 해결이 시급한 상황이었습니다.
새로운 인프라의 목표
이러한 문제들을 해결하기 위해 다음과 같은 명확한 목표를 설정했습니다.
- 안정적인 서비스: 대규모 트래픽에도 오류가 없는 견고한 서비스를 구축한다.
- 완벽한 자동화: 부족한 유지보수 인력을 고려하여, 배포부터 운영까지 전 과정을 자동화한다.
- 코드형 인프라 (IaC): 모든 인프라 자원을 코드로 관리하여 변경 이력을 추적하고 관리를 용이하게 한다.
- 비용 효율화: 최적화된 자원 사용으로 운영 비용을 절감한다.
근본 원인: Cloud Run과 비동기 처리의 한계
문제의 근원은 기존 아키텍처의 핵심인 Cloud Run과 Google Tasks의 조합에 있었습니다.
Cloud Run은 stateless(무상태성)를 특징으로 하는 서버리스 컨테이너 서비스입니다. 이 때문에 Celery와 같은 상태 기반의 워커를 안정적으로 운영하기 어려웠고, 그 대안으로 Google Tasks를 사용한 것으로 보입니다. 하지만 이 구조는 다음과 같은 한계를 가졌습니다.
- 컨테이너 간 상태 공유의 어려움
- 지속적인 워커 프로세스 부재로 인한 불안정한 큐 기반 비동기 처리
기존 아키텍처의 흐름
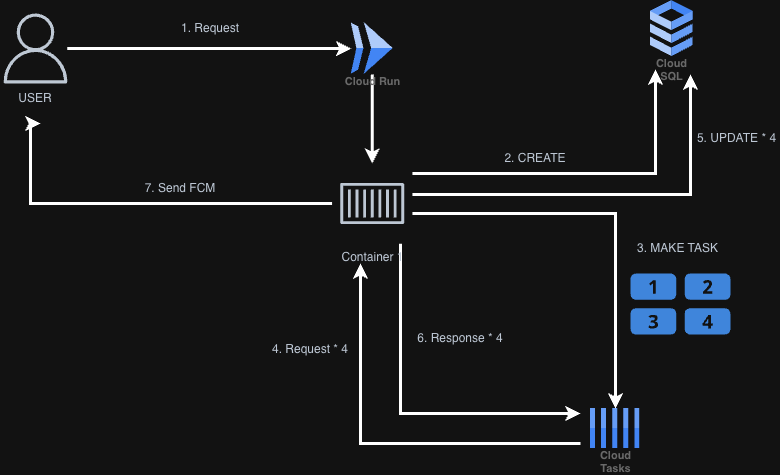
- 사용자가 요청을 보냅니다.
- DB에 Task 상태 관리를 위한 데이터를 생성합니다.
- Cloud Tasks에 n개의 Task를 생성하고, 사용자는 즉시 응답을 받습니다.
- Cloud Tasks는 생성된 Task 수만큼 다시 서버 컨테이너를 호출합니다.
- DB에 Task 성공/실패 여부를 업데이트합니다.
- Task 결과를 Cloud Tasks로 응답합니다.
- 최종 완료 상태를 FCM으로 사용자에게 알립니다.
이 구조에서 사용자의 요청 1개는
1 + (Task 개수 * n)만큼의 서버 요청을 유발했습니다. 서비스가 성장함에 따라 이 방식은 컨테이너에 엄청난 부하를 주었고, 에러를 막기 위해 수백 개의 인스턴스가 확장되면서 서버리스의 장점인 비용 효율성이 사라졌습니다.
또한, 실패한 작업을 모니터링하기 매우 어려웠고, 새로운 비동기 작업을 추가할 때마다 불필요한 코드 작성과 수작업이 반복되는 문제도 있었습니다.
새롭게 설계한 GKE 아키텍처

- 사용자의 요청은 GKE의 Main Node로 전달됩니다.
- Main Node의 Pod는 Redis에 처리할 이벤트를 추가하고, 사용자는 즉시 응답을 받습니다.
- Worker Node에서 실행 중인 Celery 워커가 Redis의 이벤트를 가져와 작업을 수행합니다.
- (필요시) 작업 상태를 DB에 기록하여 모니터링에 활용합니다.
- 모든 작업이 완료되면 Worker Node의 Pod가 FCM을 발송합니다.
부가 개선 사항
- Redis 메시지 브로커: Pub/Sub 서비스도 좋은 대안이지만, 이미 캐시 목적으로 사용하던 Redis를 메시지 브로커로도 활용하여 인프라 복잡도를 낮추고 비용을 절감했습니다.
- ArgoCD (GitOps): Git 리포지토리의 변경 사항을 감지하여 자동으로 배포를 진행합니다.
- HPA (Horizontal Pod Autoscaler): CPU, 메모리 사용량에 따라 워커 파드를 자동으로 확장/축소합니다.
- Helm Chart:
values.yaml파일로 환경별 배포 설정을 표준화하고 관리를 간소화합니다.- Prometheus + Grafana: GKE 클러스터의 상태를 실시간으로 모니터링합니다.
자동화된 배포 파이프라인
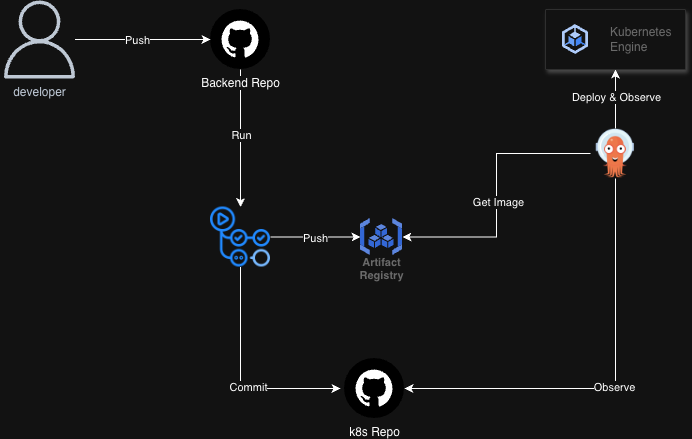
- 개발자가 코드를
backend리포지토리에 Push합니다. - GitHub Actions 워크플로우가 실행됩니다.
- 컨테이너 이미지를 빌드하여 GCP Artifact Registry에 Push합니다.
- 변경된 이미지 태그를
k8s리포지토리에 Commit합니다.
- ArgoCD가
k8s리포지토리의 변경을 감지합니다. - ArgoCD는 새로운 컨테이너 이미지를 가져와 GKE 클러스터에 배포합니다.
개선점 총정리
이번 인프라 전환을 통해 다음과 같은 놀라운 개선을 이룰 수 있었습니다.
- 부하 감소: 메인 서비스와 비동기 작업을 분리하여 시스템 전체의 부하가 크게 줄었습니다.
- 비용 절감: 인프라 비용이 약 90% 감소했습니다.
- 장애 감소: 기존 대비 장애 발생률이 90% 이상 감소했습니다.
- 안정성 향상: 불필요한 DB 쿼리가 줄어들면서 안정성이 높아졌습니다.
- 완벽한 배포 자동화: IaC와 GitOps를 통해 배포 과정이 획기적으로 간소화되었습니다.
- 모니터링 강화: 문제 발생 시 원인을 더 명확하고 빠르게 파악할 수 있게 되었습니다.
- 유지보수 효율화: 신규 비동기 작업 추가가 매우 간편해졌습니다.
- 기존: Cloud Tasks 생성 코드, 실행 코드, 통신 엔드포인트 등 복잡한 작업 필요
- 변경: Celery에 작업(Task)을 등록하는 간단한 코드로 변경
마무리
Cloud Run에서 GKE로의 전환은 단순히 기술 스택을 바꾸는 것을 넘어, 서비스의 안정성, 확장성, 비용 효율성, 그리고 개발 생산성까지 모든 면에서 긍정적인 변화를 가져온 성공적인 프로젝트였던것 같습니다.
'Infra > GCP' 카테고리의 다른 글
| GKE에서 Outbound IP 고정하기 (0) | 2025.03.11 |
|---|